El objetivo de este trabajo es analizar las diferencias que existen en la creación de contenido en netflix. Compararemos Las películas con las series, observaremos las diferencias entre países, y los autores más relevantes, entre otras cosas.
Pd: Hay un botón arriba a la derecha para cambiar a modo oscuro
Vamos a utilizar unos database previamente descargados provenientes de kaggle, una web muy conocida entre la comunidad de Data Science que tiene la finalidad de conectar, compartir y realizar análisis de todo tipo de casos, haciendo pública la obtención de los datos.
Código
#Librerias Preliminareslibrary(wordcloud2)library(readr)library(ggplot2)library(tidyverse)library(dplyr)library(ggtext)library(tidyr)library(stringr)library(gt)library(DT)#LIMPIEZA DATOS NETFLIX----#Empezaos llamando/creando a los dataframesurl_netflix <-"./datos/netflix/titles.csv"url_autor_net <-"./datos/netflix/credits.csv"df_cred_net <-read.csv(url_autor_net)df_net <-read.csv(url_netflix)#Limpieza del dataframe de directoresdf_cred_net_01 <- df_cred_net |>filter(role =="DIRECTOR")df_cred_net_02 <-na.omit(df_cred_net_01) |>select(!c(character,role, person_id))#Limpieza dataframe películas#¿Cuantos NA hay en cada variable del dataframe?cantidad_na_por_columna <-colSums(is.na(df_net))print(cantidad_na_por_columna)#> id title type #> 0 0 0 #> description release_year age_certification #> 0 0 0 #> runtime genres production_countries #> 0 0 0 #> seasons imdb_id imdb_score #> 3831 0 468 #> imdb_votes tmdb_popularity tmdb_score #> 484 76 252#¿Sigo? Cont.df_net_01 <- df_net |>select(!c(seasons, description, age_certification, imdb_id, tmdb_score))df_net_01 <- df_net_01 |>na.omit(df_net_01)df_netflix <- df_net_01 |> dplyr::rename(year = release_year,score = imdb_score,votes = imdb_votes,popularity = tmdb_popularity )cantidad_na_por_columna <-colSums(is.na(df_netflix))print(cantidad_na_por_columna)#> id title type #> 0 0 0 #> year runtime genres #> 0 0 0 #> production_countries score votes #> 0 0 0 #> popularity #> 0#de locosdf_netflix_director <- df_netflix |>left_join(df_cred_net_02, by="id")#En los actores que no se sabe el nombre ponemos unknown para que, al eliminar los NA de los otros sitios no elimine también estos datos (que son menos útiles)df_netflix_director$name <-ifelse(is.na(df_netflix_director$name), "UNKNOWN", df_netflix_director$name)df_netflix_director <- df_netflix_director |>na.omit() |> dplyr::rename(Director = name)#Finalizado y nos quedamos con el finalrm(list =ls()[!ls() %in%c("df_netflix", "df_netflix_director")])#He creado 2 dataframes porqué en el de los autores, como hay películas/series que son producidas por varias personas se repiten, y para no alterar los analisis duplicando películas lo he hecho en 2.# Lo mismo haré con las siguientes plataformas
Evolución del contenido
Código
evolution_netflix <- df_netflix |>select(title, type, year)evo_net_show <- evolution_netflix |>filter(type =="SHOW") |>group_by(year) |>summarise(num_shows =n())evo_net_movie <- evolution_netflix |>filter(type =="MOVIE") |>group_by(year) |>summarise(num_movies =n())comb_evo_type_net <-inner_join(evo_net_show,evo_net_movie, by = ("year"), suffix =c("_Movie", "_Show")) |>filter(year >=2000& year !=2023)comb_evo_long_net <- comb_evo_type_net |> tidyr::pivot_longer(cols =c(num_shows, num_movies), names_to ="type", values_to ="total")ggplot(comb_evo_long_net, aes(x =as.factor(year), y = total, fill = type)) +labs(title ="Creación de contenido a lo largo de los años por <span style='color:#E50914'><b>Movie</b></span> &<span style='color:#564d4d'><b>TV Show </b></span>")+geom_bar(stat ="identity", position ="dodge", width =0.9)+scale_fill_manual(values =c("#E50914","#564d4d"))+scale_y_continuous(sec.axis =sec_axis(~.,name="total"))+#Encontrar esto = 1h+theme_void()+theme(axis.text.x =element_text(angle =90, vjust =1, hjust=0.5), #años verticalplot.title =element_markdown(margin =margin(b =10),face ="bold", hjust =0.5), #usar html en el títuloaxis.text.y =element_text(hjust =0),legend.position ="none",plot.margin =margin(0, 0.3, 0.2, -0.63, unit ="cm"), )
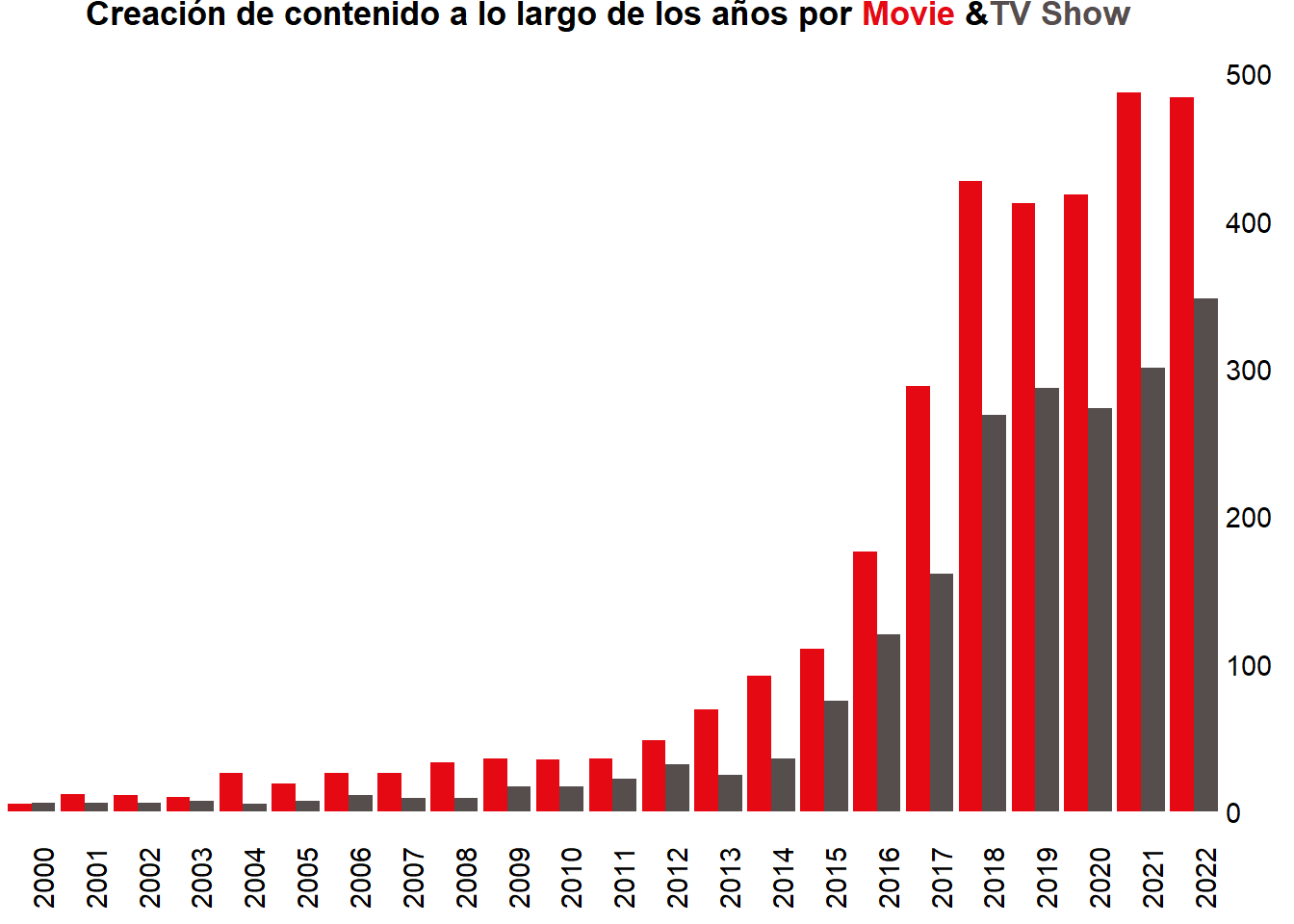
El gráfico muestra la evolución de la creación de contenido en los últimos 22 años, desde 2000 hasta 2022. Se divide en dos categorías: Películas(rojo) y series de televisión(marrón).
Películas
En el caso de las películas, se observa una tendencia creciente a lo largo de los años, con un aumento de más del 200% desde 2000. El crecimiento es más pronunciado en los últimos años, con un aumento de más de 50% en la última década.
Este crecimiento se puede atribuir a varios factores, entre los que destacan:
-El aumento de la popularidad de las plataformas de streaming, como Netflix, HBO Max y Disney+, que han creado una mayor demanda de contenido original. -El desarrollo de nuevas tecnologías de producción, como la animación por ordenador, que han reducido los costes y han facilitado la creación de contenido de mayor calidad. -La globalización de la industria cinematográfica, que ha permitido a los creadores de contenido llegar a una audiencia más amplia.
Series de televisión
En el caso de las series de televisión, también se observa una tendencia creciente a lo largo de los años, con un aumento de más del 300% desde 2000. El crecimiento es más pronunciado en la última década, con un aumento de más del 150%.
Este crecimiento se debe a factores similares a los que han impulsado el crecimiento de las películas, como el aumento de la popularidad de las plataformas de streaming y el desarrollo de nuevas tecnologías de producción. Además, las series de televisión han experimentado una serie de cambios en los últimos años que las han hecho más atractivas para los espectadores, como:
-La diversificación de los géneros y formatos, con el auge de las series de comedia, drama, terror, fantasía, ciencia ficción, etc. -La mayor duración de las temporadas, que ha permitido a los creadores de contenido desarrollar historias más complejas. -La incorporación de nuevos actores y actrices, que han atraído a nuevos espectadores.
Conclusiones
En general, el gráfico muestra que la creación de contenido, tanto de películas como de series de televisión, ha experimentado un crecimiento significativo en los últimos años. Este crecimiento se debe a una serie de factores, entre los que destacan el aumento de la popularidad de las plataformas de streaming, el desarrollo de nuevas tecnologías de producción y la globalización de la industria.
Se espera que esta tendencia continúe en los próximos años, ya que las plataformas de streaming siguen creciendo y las nuevas tecnologías de producción siguen desarrollándose.
Comparación Series Vs Películas
Oferta de streaming Netflix
Código
#Gráfico Porcentaje Películas Vs Series----tipos_netflix <- df_netflix |>count(type) |>mutate(porcentaje = n /sum(n) *100) #Voy a cambiar el nombre de dentro de las variable typetipos_netflix$type <-gsub("MOVIE", "Movie", tipos_netflix$type, ignore.case =TRUE)tipos_netflix$type <-gsub("SHOW", "TV Show", tipos_netflix$type, ignore.case =TRUE)#printf("%.1f%%", ...) Para coger solo 1 decimaltipos_netflix$porcentaje <-sprintf("%.f%%", tipos_netflix$porcentaje)#Creamos una variable que contenga tanto el tipo como el porcentaje para hacerlo luego bonitotipos_netflix$etiqueta <-paste(tipos_netflix$porcentaje, tipos_netflix$type, sep ="\n")# Suponiendo que conteo_tipos es tu dataframe con el conteo y porcentajeggplot(tipos_netflix, aes(x ="", y = porcentaje, fill = type)) +geom_bar(stat ="identity", width =0.4) +geom_text(aes(label = etiqueta), position =position_stack(0.5), size =10, color ="white", fontface ="bold") +scale_fill_manual(values =c("#B81D24", "#564d4d")) +# Colores personalizadoscoord_flip()+theme_void()+theme(legend.position ="none")#He estado 3h mínimo para hacer esta gráfica (para poner el texto + % dentro... locura)
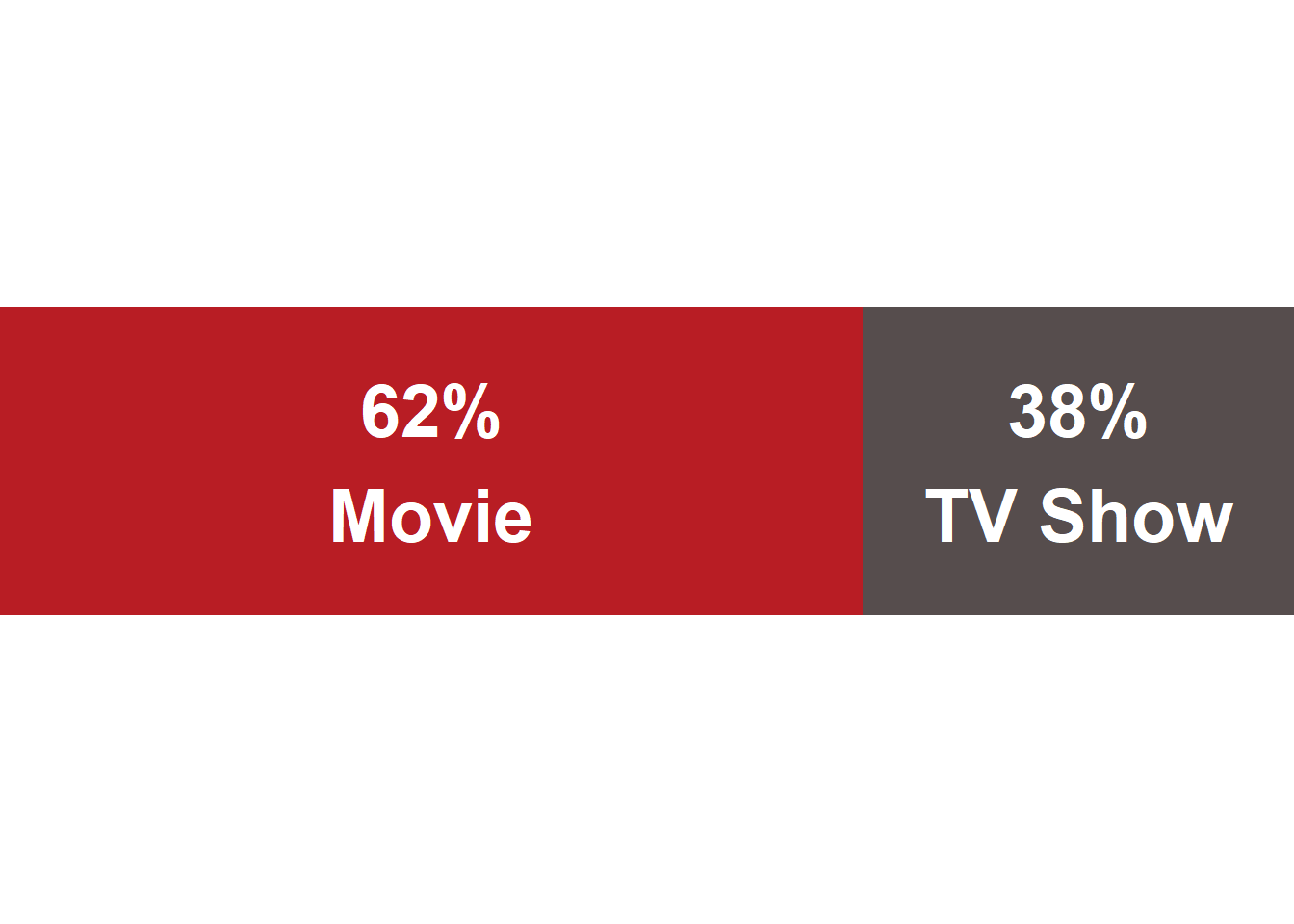
El gráfico muestra la composición del contenido de Netflix en términos de películas y series de televisión. La barra roja representa el porcentaje de películas, mientras que la barra marrón representa el porcentaje de series de televisión. Como podemos observar, Netflix ofrece una amplia variedad de contenido, con un enfoque especial en las películas, donde estas representan el 62% del contenido de Netflix, mientras que las series de televisión representan el 38%.
Este resultado se debe a varios factores. En primer lugar, las películas son un tipo de contenido popular que atrae a una amplia audiencia, además de que Netflix ha invertido mucho en la producción de películas originales, que han tenido un gran éxito en la actualidad.
Oferta Streaming por paises
Código
#GRAFICOS DE BARRAS SERIES VS PELIS RESPECTO AL PAIS----#En primer lugar vamos a desglosarlo por paises, ya que hay pelis que estan producidas en varios países#Para descubrir como se hacía esto he tenido que venderle mi alma al diablodf_netflix_long <- df_netflix |>select(c(title, type, production_countries)) |>separate_rows(production_countries, sep =", ") |>filter(!is.na(production_countries))df_netflix_long$production_countries <-str_replace_all(df_netflix_long$production_countries,"[\\[\\]']", "")#Vamos a contar MOVIE Y SHOW producido en cada paísdf_netflix_long <- df_netflix_long |>group_by(production_countries, type) |>summarise(count =n())df_netflix_long <- df_netflix_long |>group_by(production_countries) |>mutate(total =sum(count)) |>ungroup()#Eliminamos las filas que no contengan nada (NA)df_netflix_long <- df_netflix_long |>filter(!is.na(production_countries) & production_countries !="")#Ordenamos dataframe y seleccionamos los 10 primeros (20 porque son 2 por país)df_netflix_long <- df_netflix_long |>arrange(desc(total))top_country_netflix <-head(df_netflix_long, 20)#Creamos 2 nuevas variables con el % respecto al total (MOVIE y SHOW)top_country_netflix <- top_country_netflix |>group_by(production_countries) |>summarise(percentage_movie = (count[type =="MOVIE"] / total) *100,percentage_show = (count[type =="SHOW"] / total) *100) |>ungroup()#Tenemos los datos duplicados, hay que coger solo 1 de cada paístop_country_netflix <- top_country_netflix |>distinct(production_countries, .keep_all =TRUE)#Vamos a cambiar los nombres de los países para que se vea mejor luego al graficarlotop_country_netflix <- top_country_netflix |>mutate(production_countries =case_when( production_countries =="KR"~"Korea", production_countries =="JP"~"Japón", production_countries =="GB"~"UK", production_countries =="US"~"USA", production_countries =="MX"~"México", production_countries =="ES"~"España", production_countries =="FR"~"Francia", production_countries =="CA"~"Canada", production_countries =="DE"~"Turquía", production_countries =="IN"~"Índia", ))#Y ordenamos de más a menos respecto SHOWtop_country_netflix <- top_country_netflix |>arrange(desc(percentage_show))#Pasamos a long para que lo pueda interpretar mejortop_country_netflix_long <- top_country_netflix |>pivot_longer(cols =c(percentage_movie, percentage_show),names_to ="type",values_to ="percentage")#Tenemos que pasar a factor la variable production_countries para que no se bugueetop_country_netflix_long$production_countries <-factor(top_country_netflix_long$production_countries, levels =unique(top_country_netflix_long$production_countries))#Grafíco#Redondeamos a 1 decimal y ponemos el símbolo %top_country_netflix_long$percentage <-round(top_country_netflix_long$percentage, 1)#si hago esto se rompe, no se porque#top_country_netflix_long$percentage <- paste0(top_country_netflix_long$percentage, "%")ggplot(top_country_netflix_long, aes(x = production_countries, y = percentage, fill = type)) +geom_bar(stat ="identity",position ="stack", width =0.5)+coord_flip()+scale_fill_manual(values =c("percentage_movie"="#E50914", "percentage_show"="#564d4d"))+geom_text(aes(label = percentage), position =position_stack(0.5), size =3, color ="white")+labs(title ="Top paises creadores de cine por <span style='color:#E50914'><b>Movie</b></span> &<span style='color:#564d4d'><b>TV Show </b></span> <br><span style='font-size:10pt;'><i>(Representado en %)</i></span>")+theme_minimal()+theme(legend.position ="none",plot.title =element_markdown(margin =margin(b =10),face ="bold", hjust =0.5),axis.title.x =element_blank(),axis.title.y =element_blank(),axis.text.x =element_blank(),panel.grid.major.x =element_blank(),panel.grid.minor.x =element_blank(),panel.grid.minor.y =element_blank(), panel.grid.major.y =element_blank(), )+scale_y_reverse()# DIOS ESTE GRÁFICO, PA VOLVERSE LOCO, creo que a medida que hago más gráficos son más costosos#Fino señores
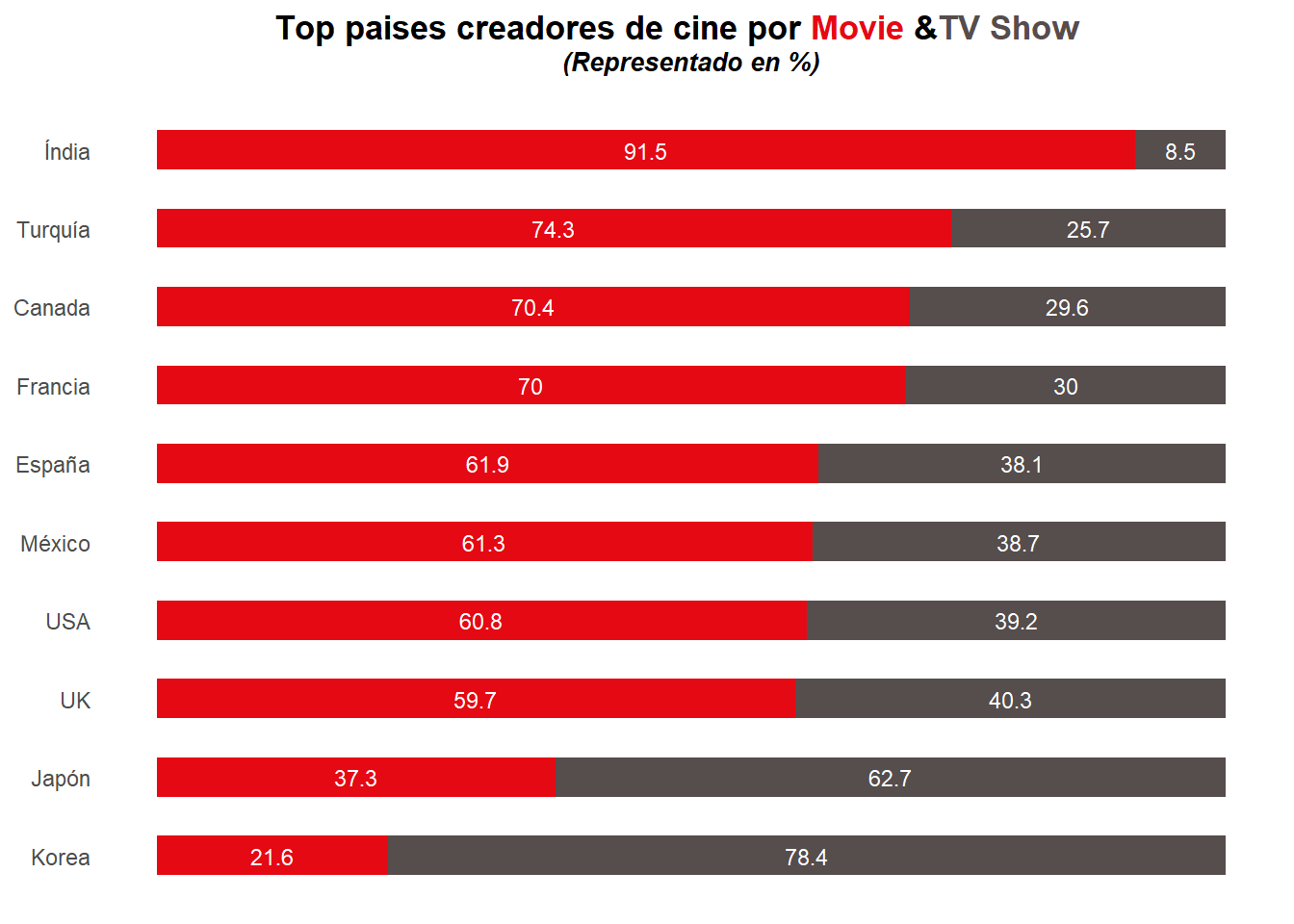
La gráfica muestra los diez países que producen más películas y series de televisión en el mundo, segmentado por categoría. Los países se ordenan de mayor a menor producción, según el porcentaje de películas.
Como se puede ver, India es el país que tiene una mayor proporción de creación de películas del ranking con un 91.5%. A continuación tenemos a Turquía, con un 74.3% (con sus importantes películas turcas que todos conocemos), y Canada y Francia que producen aproximádamente un 70% películas. En el otro extremo, podemos encontrar a los países asiáticos, Korea y Japón, caracterizados por hacer series de animación o acción y aventura, como “El juego del calamar”. Estas se han especializado en la creación de series de televisión/anime, siendo su producción un 78.4% y 62.7% sobre el total de su producción. Por otro lado, podemos observar ciertos países que se decantan más por la creación de películas pero que, aún así, está muy parejo, rondando todos el 60% en películas y el restante 40% en series. Estos son, España, México, Estados Unidos y Reino Unido.
El gráfico muestra una tendencia general a la creciente importancia de los países emergentes en la producción de cine y televisión. India, Turquía y Canadá son ejemplos de países que han experimentado un crecimiento significativo en la producción de cine y televisión en los últimos años. En contraposición, también muestra la importancia de los mercados internacionales para la industria cinematográfica y televisiva. Los países que aparecen en este ranking son aquellos que producen películas y programas de televisión que tienen éxito en todo el mundo.
Ranking de géneros por nota
Código
#Ranking/Valoración de los géneros en netflix-----#Seleccionamos los datos que vamos a utilizar y filtrarlos para quitarnos las notas sesgadas (pocos votos)df_generos_net <- df_netflix |>select(title, type, genres, score, votes) |>filter(votes>4000) |>select(-votes)#Vamos a desglosarlo, ya que una película puede tener varios génerosgeneros_net <- df_generos_net |>separate_rows(genres, sep =", ") |>filter(!is.na(genres)) generos_net$genres <-str_replace_all(generos_net$genres,"[\\[\\]']", "")#En un principio vamos a hacer el analisis sobre Moviesgeneros_net <- generos_net |>filter(type =="MOVIE") |>select(-type)#Eliminamos las categorías menos conocidasgeneros_net <- generos_net |>filter(!(genres %in%c("war", "sport", "european","family", "fantasy")))#Vamos a hacer un filtro seleccionando las 80 mejores peliculas de cada categoría y hacer la media#(Se va a crear un poco de sesgo pero al fin y al cabo es para que se vea mejor)generos_net_ordenado <- generos_net |>arrange(genres, desc(score))top_100_por_genero <- generos_net_ordenado |>group_by(genres) |>slice_head(n =80)nota_generos_net <- top_100_por_genero |>group_by(genres) |>summarise(nota_media =mean(score, na.rm =TRUE))nota_generos_net$nota_media <-round(nota_generos_net$nota_media, 2)nota_generos_net <- nota_generos_net |>mutate(genres =case_when( genres =="documentation"~"documental",TRUE~ genres ))nota_generos_net$genres <- tools::toTitleCase(nota_generos_net$genres)#GRAFICA ggplot(nota_generos_net) +geom_col(aes(x =reorder(str_wrap(genres, 5), nota_media),y = (nota_media -5) /5, # Escalar la altura de las barras al rango [0, 1]fill = nota_media ),position ="dodge2",show.legend =TRUE,alpha = .9 ) +coord_polar() +scale_y_continuous(limits =c(-0.7, 1), # Ajustar los límites a [0, 1]expand =c(0, -0.4) ) +scale_fill_gradientn("Nota media del género",colours =c("#252527","#6d625c","#410a14" ,"#ed0b0e") ) +guides(fill =guide_colorsteps(barwidth =15, barheight = .5, title.position ="top", title.hjust =0.5 )) +labs(title ="Valoración de las categorías en Netflix" )+theme(axis.title =element_blank(),axis.ticks =element_blank(),axis.text.y =element_blank(),panel.grid =element_blank(),plot.title =element_text(face ="bold", size =15, hjust =0.5),panel.background =element_rect(fill ="white", color ="white"),panel.grid.major.x =element_blank(),axis.text.x =element_text(color ="#252527", size =11, hjust =0.5),legend.position ="bottom",legend.title =element_text(color ="#252527") )
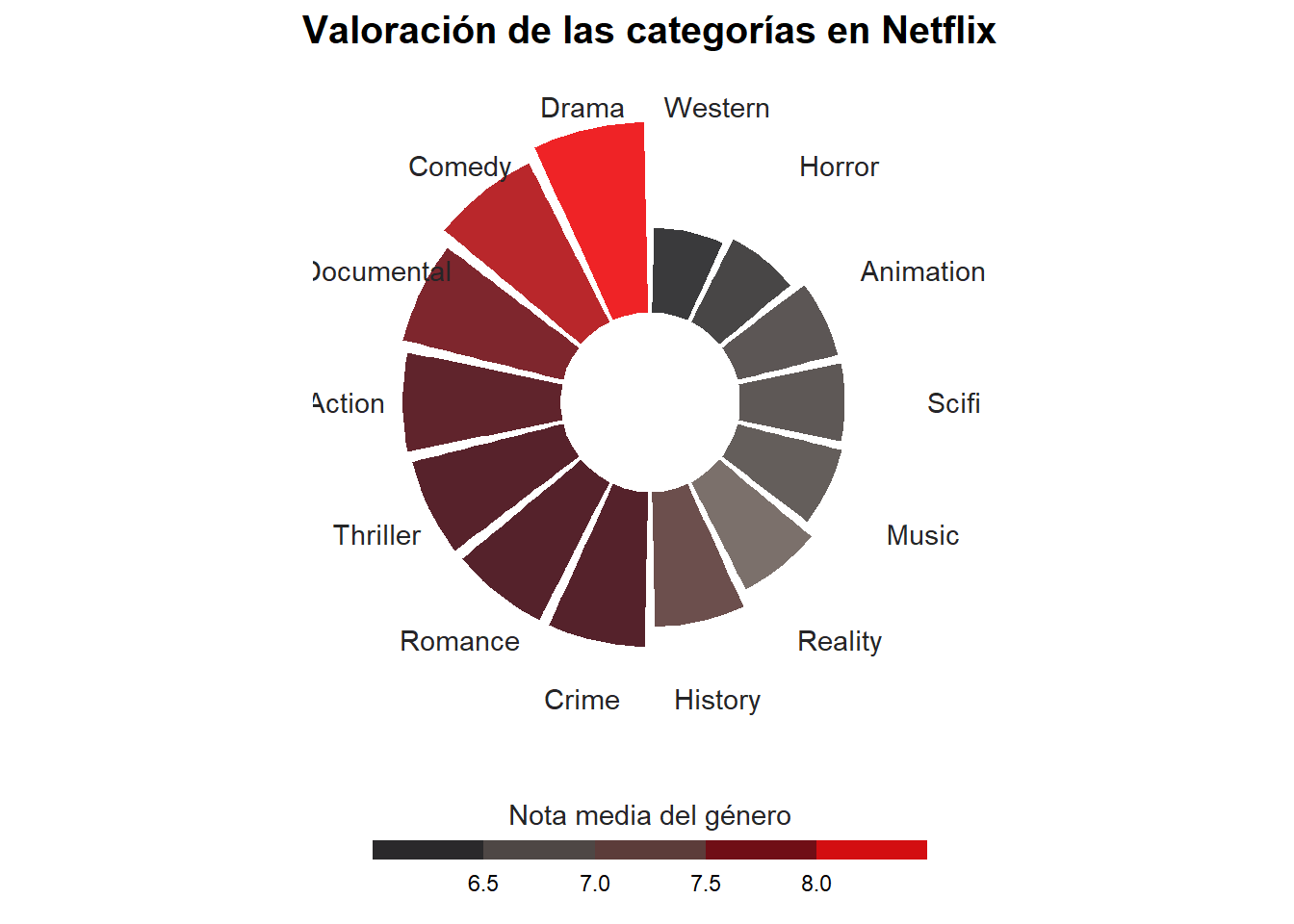
Esta gráfica muestra la valoración media de las categorías de contenido en Netflix, según las puntuaciones de los usuarios. Las categorías se ordenan de menor a mayor según el sentido de las agujas del reloj, yendo con un color más oscuro y negro, lás menos valoradas, a un rojo más vivo, siendo estas las mejor valoradas por la audiencia. En primer lugar, podemos observar como las categorías más mainstream son más valoradas, siendo estas Drama y Comedia, con una nota de 8.2 y 8 respectivamente. A continuación tenemos un grupo de categorías, también muy bien valoradas con una nota muy similar, que oscilan entre 7.25 hasta 7.75. Estas son Documental, Action, Thriller, Romance y Crime, de más valorado a menos. Por último, se hallan las categorías peor valoradas de netflix, con una nota que va desde 6.4, la menos valorada, hasta 6.8. Entre estas podemos destacar a Wester y Horrror que son las peores.
En general, las categorías de contenido más valoradas en Netflix son aquellas que ofrecen historias complejas e interesantes, que pueden generar una mayor conexión con los espectadores y aceptadas por un público más amplio (son más para todos los públicos).En cambio, las categorías peor valoradas son aquellas que pueden ser polarizadoras o que pueden no ofrecer una experiencia tan gratificante para los espectadores.
table_show_net <- df_netflix |>filter(type =="SHOW") |>filter(votes >70000) |>select(c(year, title, genres, production_countries, score)) |>arrange(desc(score)) |>slice_head(n=10)table_show_net <- table_show_net |> dplyr::rename( Año = year, Título = title, Géneros = genres, Producción = production_countries,Nota = score )table_show_net |>gt() |>tab_header(title =md("**Top 10** mejores **series** de Netflix"),subtitle =md("*Dentro de las más valoradas*")) |>tab_footnote(footnote =md("*Producción propia a partir de datos de `kaggle`*"))
Aquí podemos observar el top 10 de las mejores series de Netflix valoradas por el público, de forma descendiente. Práctiamente todas tienen una nota de excelente, pero hay varias cosas que se pueden observar. En primer lugar, dentro del top, podemos ver como hay una clara predominación de series producidas en Estados Undidos, que puede deberse, o porque producen una mayor cantidad de series o que gracias a esto han aprendido y se han hecho mejores cinematográficamente. La más destacada “Breaking Bad” En segundo lugar, podemos observar como Japón, con sus animes se apodera de prácticamente la otra mitad del podio, entre ellos “Death Note”, “Attack on Titan” o “One Piece”.
Código
table_movie_net <- df_netflix |>filter(type =="MOVIE") |>filter(votes >42000) |>select(c(year, title, genres, production_countries, score)) |>arrange(desc(score)) |>slice_head(n=10)table_movie_net <- table_movie_net |> dplyr::rename( Año = year, Título = title, Géneros = genres, Producción = production_countries,Nota = score)table_movie_net |>gt() |>tab_header(title =md("**Top 10** mejores **películas** de Netflix"),subtitle =md("*Dentro de las más valoradas*")) |>tab_footnote(footnote =md("*Producción propia a partir de datos de `kaggle`*"))
Top 10 mejores películas de Netflix
Dentro de las más valoradas
Año
Título
Géneros
Producción
Nota
2008
The Dark Knight
['drama', 'thriller', 'action', 'crime']
['GB', 'US']
9.0
2003
The Lord of the Rings: The Return of the King
['fantasy', 'action', 'drama']
['NZ', 'US']
9.0
1994
Forrest Gump
['comedy', 'drama', 'romance']
['US']
8.8
2001
The Lord of the Rings: The Fellowship of the Ring
['fantasy', 'action', 'drama']
['NZ', 'US']
8.8
2002
The Lord of the Rings: The Two Towers
['action', 'fantasy', 'drama']
['NZ', 'US']
8.8
2021
Bo Burnham: Inside
['comedy', 'drama', 'music', 'reality']
['US']
8.7
2009
3 Idiots
['drama', 'comedy']
['IN']
8.4
1973
The Sting
['crime', 'drama', 'comedy', 'music']
['US']
8.3
1992
Reservoir Dogs
['thriller', 'crime', 'drama']
['US']
8.3
2007
Like Stars on Earth
['drama', 'family']
['IN']
8.3
Producción propia a partir de datos de kaggle
Aquí, podemos observar la misma tendencia, como Estados Unidos es la mayor productora de las mejores películas. En cambio, podemos ver una curiosa casualidad y es que las 3 películas de El señor de los anillos estan dentro del podio, con notas que van del 9 al 8.8.
Código
#Tabla para buscar informacióndf_buscar_net <- df_netflix_director |>select(-c(id, votes, popularity))datatable(df_buscar_net)
Directores con más películas
Código
#Gráfico de Nombres de TOP DIRECTORES en NETFLIX----df_netflix_dir <- df_netflix_director |>count(Director, name ="cantidad", sort =TRUE)df_netflix_dir <- df_netflix_dir |>filter(Director !="UNKNOWN") |>mutate(Director =as.factor(Director))wordcloud2(df_netflix_dir, size=0.6, color=rep_len( c("#B81D24","#564d4d"), nrow(df_netflix_dir)),backgroundColor ="#000000")
Este gráfico representa a los directores con mas predominancia en los cines de Netflix de una forma más creativa, visual y bonita. Siempre respetando la paleta de colores de netflix. Brevemente, se puede observar como el mayor tamaño de los nombres indica un mayor número de obras realizadas. En este caso, el mayor productor es Raúl Campos, seguido de Jan Suter y Ryan Polito.
Información extra
En este trabajo me he inspirado en una web donde hay una galería de todos los posibles gráficos que pueden crearse con ggplot2, llamado R-graph-gallery, podéis acceder aquí. Por otro lado, este trabajo no hubiera podido ser posible si no fuese por kaggle, de donde he adquirido los dataframes y, además, me he inspirado de otros trabajos / gráficos. Podéis acceder aquí. Se ha intentado seguir una mejor coherencia durante todo el trabajo y se ha respetado a la perfección la paleta de colores que representa netflix. Para finalizar, he de explicar que he modificado / alterado los dataframes a la hora de filtrarlos etc. Es decir, estan sesgados para que la representación sea más notoria y bonita. Por tanto, puede que en algún caso no coincida algún dato con análisis externos a este trabajo. Por ejemplo, el ranking de géneros por nota, si selecciono todas las categorías sin a penas filtración todos tienen la misma nota.
Ejecutar el código
---title: "Análisis de la plataforma de streaming NETFLIX"description: | Comparativa y análisis de películas, series, géneros, autores...author: - name: Joel Seguí Far affiliation: Universitat de València affiliation-url: https://www.uv.esdate: 2024-01-24 #--categories: [Trabajo BigData, Netflix] #--image: "./imagenes/imagen_01.png"title-block-banner: true #- {true, false, "green","#AA0000"}title-block-banner-color: "white" #-"#FFFFFF" toc-depth: 3smooth-scroll: trueformat: html: #backgroundcolor: "#F1F3F4" #embed-resources: true link-external-newwindow: true #css: ./assets/my_css_file.css #- CUIDADO!!!!code-tools: truecode-link: true---## IntroducciónEl objetivo de este trabajo es analizar las diferencias que existen en la creación de contenido en netflix. Compararemos Las películas con las series, observaremos las diferencias entre países, y los autores más relevantes, entre otras cosas.*Pd: Hay un botón arriba a la derecha para cambiar a modo oscuro*## Datos del trabajo:::{.panel-tabset}## DatosVamos a utilizar unos database previamente descargados provenientes de `kaggle`, una web muy conocida entre la comunidad de Data Science que tiene la finalidad de conectar, compartir y realizar análisis de todo tipo de casos, haciendo pública la obtención de los datos.## Código```{r}#Librerias Preliminareslibrary(wordcloud2)library(readr)library(ggplot2)library(tidyverse)library(dplyr)library(ggtext)library(tidyr)library(stringr)library(gt)library(DT)#LIMPIEZA DATOS NETFLIX----#Empezaos llamando/creando a los dataframesurl_netflix <-"./datos/netflix/titles.csv"url_autor_net <-"./datos/netflix/credits.csv"df_cred_net <-read.csv(url_autor_net)df_net <-read.csv(url_netflix)#Limpieza del dataframe de directoresdf_cred_net_01 <- df_cred_net |>filter(role =="DIRECTOR")df_cred_net_02 <-na.omit(df_cred_net_01) |>select(!c(character,role, person_id))#Limpieza dataframe películas#¿Cuantos NA hay en cada variable del dataframe?cantidad_na_por_columna <-colSums(is.na(df_net))print(cantidad_na_por_columna)#¿Sigo? Cont.df_net_01 <- df_net |>select(!c(seasons, description, age_certification, imdb_id, tmdb_score))df_net_01 <- df_net_01 |>na.omit(df_net_01)df_netflix <- df_net_01 |> dplyr::rename(year = release_year,score = imdb_score,votes = imdb_votes,popularity = tmdb_popularity )cantidad_na_por_columna <-colSums(is.na(df_netflix))print(cantidad_na_por_columna)#de locosdf_netflix_director <- df_netflix |>left_join(df_cred_net_02, by="id")#En los actores que no se sabe el nombre ponemos unknown para que, al eliminar los NA de los otros sitios no elimine también estos datos (que son menos útiles)df_netflix_director$name <-ifelse(is.na(df_netflix_director$name), "UNKNOWN", df_netflix_director$name)df_netflix_director <- df_netflix_director |>na.omit() |> dplyr::rename(Director = name)#Finalizado y nos quedamos con el finalrm(list =ls()[!ls() %in%c("df_netflix", "df_netflix_director")])#He creado 2 dataframes porqué en el de los autores, como hay películas/series que son producidas por varias personas se repiten, y para no alterar los analisis duplicando películas lo he hecho en 2.# Lo mismo haré con las siguientes plataformas```:::---# Evolución del contenido```{r}evolution_netflix <- df_netflix |>select(title, type, year)evo_net_show <- evolution_netflix |>filter(type =="SHOW") |>group_by(year) |>summarise(num_shows =n())evo_net_movie <- evolution_netflix |>filter(type =="MOVIE") |>group_by(year) |>summarise(num_movies =n())comb_evo_type_net <-inner_join(evo_net_show,evo_net_movie, by = ("year"), suffix =c("_Movie", "_Show")) |>filter(year >=2000& year !=2023)comb_evo_long_net <- comb_evo_type_net |> tidyr::pivot_longer(cols =c(num_shows, num_movies), names_to ="type", values_to ="total")ggplot(comb_evo_long_net, aes(x =as.factor(year), y = total, fill = type)) +labs(title ="Creación de contenido a lo largo de los años por <span style='color:#E50914'><b>Movie</b></span> &<span style='color:#564d4d'><b>TV Show </b></span>")+geom_bar(stat ="identity", position ="dodge", width =0.9)+scale_fill_manual(values =c("#E50914","#564d4d"))+scale_y_continuous(sec.axis =sec_axis(~.,name="total"))+#Encontrar esto = 1h+theme_void()+theme(axis.text.x =element_text(angle =90, vjust =1, hjust=0.5), #años verticalplot.title =element_markdown(margin =margin(b =10),face ="bold", hjust =0.5), #usar html en el títuloaxis.text.y =element_text(hjust =0),legend.position ="none",plot.margin =margin(0, 0.3, 0.2, -0.63, unit ="cm"), )```El gráfico muestra la evolución de la creación de contenido en los últimos 22 años, desde 2000 hasta 2022. Se divide en dos categorías: **Películas** *(rojo)* y **series de televisión** *(marrón)*.**Películas**En el caso de las películas, se observa una **tendencia creciente** a lo largo de los años, con un aumento de más del 200% desde 2000. El crecimiento es más pronunciado en los últimos años, con un aumento de más de 50% en la última década.Este crecimiento se puede atribuir a varios factores, entre los que destacan: -El **aumento de la popularidad de las plataformas de streaming**, como Netflix, HBO Max y Disney+, que han creado una mayor demanda de contenido original.<br> -El desarrollo de nuevas tecnologías de producción, como la animación por ordenador, que han **reducido los costes** y han facilitado la creación de contenido de mayor calidad.<br> -La **globalización de la industria cinematográfica**, que ha permitido a los creadores de contenido llegar a una audiencia más amplia.<br>**Series de televisión**En el caso de las series de televisión, también se observa una **tendencia creciente** a lo largo de los años, con un aumento de más del 300% desde 2000. El crecimiento es más pronunciado en la última década, con un aumento de más del 150%.Este crecimiento se debe a factores similares a los que han impulsado el crecimiento de las películas, como el aumento de la popularidad de las plataformas de streaming y el desarrollo de nuevas tecnologías de producción. Además, las series de televisión han experimentado una serie de cambios en los últimos años que las han hecho más atractivas para los espectadores, como: -La **diversificación de los géneros y formatos**, con el auge de las series de comedia, drama, terror, fantasía, ciencia ficción, etc.<br> -La **mayor duración de las temporadas**, que ha permitido a los creadores de contenido desarrollar historias más complejas.<br> -La incorporación de nuevos actores y actrices, que han atraído a nuevos espectadores.<br>**Conclusiones**En general, el gráfico muestra que la creación de contenido, tanto de películas como de series de televisión, ha experimentado un crecimiento significativo en los últimos años. Este crecimiento se debe a una serie de factores, entre los que destacan el aumento de la popularidad de las plataformas de streaming, el desarrollo de nuevas tecnologías de producción y la globalización de la industria.Se espera que esta tendencia continúe en los próximos años, ya que las plataformas de streaming siguen creciendo y las nuevas tecnologías de producción siguen desarrollándose.---# Comparación Series Vs Películas## Oferta de streaming Netflix```{r}#Gráfico Porcentaje Películas Vs Series----tipos_netflix <- df_netflix |>count(type) |>mutate(porcentaje = n /sum(n) *100) #Voy a cambiar el nombre de dentro de las variable typetipos_netflix$type <-gsub("MOVIE", "Movie", tipos_netflix$type, ignore.case =TRUE)tipos_netflix$type <-gsub("SHOW", "TV Show", tipos_netflix$type, ignore.case =TRUE)#printf("%.1f%%", ...) Para coger solo 1 decimaltipos_netflix$porcentaje <-sprintf("%.f%%", tipos_netflix$porcentaje)#Creamos una variable que contenga tanto el tipo como el porcentaje para hacerlo luego bonitotipos_netflix$etiqueta <-paste(tipos_netflix$porcentaje, tipos_netflix$type, sep ="\n")# Suponiendo que conteo_tipos es tu dataframe con el conteo y porcentajeggplot(tipos_netflix, aes(x ="", y = porcentaje, fill = type)) +geom_bar(stat ="identity", width =0.4) +geom_text(aes(label = etiqueta), position =position_stack(0.5), size =10, color ="white", fontface ="bold") +scale_fill_manual(values =c("#B81D24", "#564d4d")) +# Colores personalizadoscoord_flip()+theme_void()+theme(legend.position ="none")#He estado 3h mínimo para hacer esta gráfica (para poner el texto + % dentro... locura)```El gráfico muestra la composición del contenido de Netflix en términos de películas y series de televisión. La barra roja representa el porcentaje de películas, mientras que la barra marrón representa el porcentaje de series de televisión.<br>Como podemos observar, Netflix ofrece una amplia variedad de contenido, con un **enfoque especial en las películas**, donde estas representan el **62%** del contenido de Netflix, mientras que las **series de televisión** representan el **38%**.Este resultado se debe a varios factores. En primer lugar, las películas son un tipo de contenido popular que atrae a una amplia audiencia, además de que Netflix ha invertido mucho en la producción de películas originales, que han tenido un gran éxito en la actualidad. ---## Oferta Streaming por paises```{r}#GRAFICOS DE BARRAS SERIES VS PELIS RESPECTO AL PAIS----#En primer lugar vamos a desglosarlo por paises, ya que hay pelis que estan producidas en varios países#Para descubrir como se hacía esto he tenido que venderle mi alma al diablodf_netflix_long <- df_netflix |>select(c(title, type, production_countries)) |>separate_rows(production_countries, sep =", ") |>filter(!is.na(production_countries))df_netflix_long$production_countries <-str_replace_all(df_netflix_long$production_countries,"[\\[\\]']", "")#Vamos a contar MOVIE Y SHOW producido en cada paísdf_netflix_long <- df_netflix_long |>group_by(production_countries, type) |>summarise(count =n())df_netflix_long <- df_netflix_long |>group_by(production_countries) |>mutate(total =sum(count)) |>ungroup()#Eliminamos las filas que no contengan nada (NA)df_netflix_long <- df_netflix_long |>filter(!is.na(production_countries) & production_countries !="")#Ordenamos dataframe y seleccionamos los 10 primeros (20 porque son 2 por país)df_netflix_long <- df_netflix_long |>arrange(desc(total))top_country_netflix <-head(df_netflix_long, 20)#Creamos 2 nuevas variables con el % respecto al total (MOVIE y SHOW)top_country_netflix <- top_country_netflix |>group_by(production_countries) |>summarise(percentage_movie = (count[type =="MOVIE"] / total) *100,percentage_show = (count[type =="SHOW"] / total) *100) |>ungroup()#Tenemos los datos duplicados, hay que coger solo 1 de cada paístop_country_netflix <- top_country_netflix |>distinct(production_countries, .keep_all =TRUE)#Vamos a cambiar los nombres de los países para que se vea mejor luego al graficarlotop_country_netflix <- top_country_netflix |>mutate(production_countries =case_when( production_countries =="KR"~"Korea", production_countries =="JP"~"Japón", production_countries =="GB"~"UK", production_countries =="US"~"USA", production_countries =="MX"~"México", production_countries =="ES"~"España", production_countries =="FR"~"Francia", production_countries =="CA"~"Canada", production_countries =="DE"~"Turquía", production_countries =="IN"~"Índia", ))#Y ordenamos de más a menos respecto SHOWtop_country_netflix <- top_country_netflix |>arrange(desc(percentage_show))#Pasamos a long para que lo pueda interpretar mejortop_country_netflix_long <- top_country_netflix |>pivot_longer(cols =c(percentage_movie, percentage_show),names_to ="type",values_to ="percentage")#Tenemos que pasar a factor la variable production_countries para que no se bugueetop_country_netflix_long$production_countries <-factor(top_country_netflix_long$production_countries, levels =unique(top_country_netflix_long$production_countries))#Grafíco#Redondeamos a 1 decimal y ponemos el símbolo %top_country_netflix_long$percentage <-round(top_country_netflix_long$percentage, 1)#si hago esto se rompe, no se porque#top_country_netflix_long$percentage <- paste0(top_country_netflix_long$percentage, "%")ggplot(top_country_netflix_long, aes(x = production_countries, y = percentage, fill = type)) +geom_bar(stat ="identity",position ="stack", width =0.5)+coord_flip()+scale_fill_manual(values =c("percentage_movie"="#E50914", "percentage_show"="#564d4d"))+geom_text(aes(label = percentage), position =position_stack(0.5), size =3, color ="white")+labs(title ="Top paises creadores de cine por <span style='color:#E50914'><b>Movie</b></span> &<span style='color:#564d4d'><b>TV Show </b></span> <br><span style='font-size:10pt;'><i>(Representado en %)</i></span>")+theme_minimal()+theme(legend.position ="none",plot.title =element_markdown(margin =margin(b =10),face ="bold", hjust =0.5),axis.title.x =element_blank(),axis.title.y =element_blank(),axis.text.x =element_blank(),panel.grid.major.x =element_blank(),panel.grid.minor.x =element_blank(),panel.grid.minor.y =element_blank(), panel.grid.major.y =element_blank(), )+scale_y_reverse()# DIOS ESTE GRÁFICO, PA VOLVERSE LOCO, creo que a medida que hago más gráficos son más costosos#Fino señores```La gráfica muestra los **diez países que producen más películas y series de televisión en el mundo**, segmentado por categoría. Los países se ordenan de mayor a menor producción, según el porcentaje de películas.Como se puede ver, **India** es el país que tiene una **mayor proporción** de creación de **películas** del ranking con un 91.5%. A continuación tenemos a Turquía, con un 74.3% (con sus importantes películas turcas que todos conocemos), y Canada y Francia que producen aproximádamente un 70% películas.<br>En el otro extremo, podemos encontrar a los **países asiáticos**, Korea y Japón, caracterizados por hacer **series de animación** o acción y aventura, como "El juego del calamar". Estas se han especializado en la creación de series de televisión/anime, siendo su producción un 78.4% y 62.7% sobre el total de su producción.Por otro lado, podemos observar ciertos países que se decantan más por la creación de películas pero que, aún así, está muy parejo, rondando todos el 60% en películas y el restante 40% en series. Estos son, España, México, Estados Unidos y Reino Unido.El gráfico muestra una tendencia general a la creciente importancia de los países emergentes en la producción de cine y televisión. India, Turquía y Canadá son ejemplos de países que han experimentado un crecimiento significativo en la producción de cine y televisión en los últimos años. En contraposición, también muestra la importancia de los mercados internacionales para la industria cinematográfica y televisiva. Los países que aparecen en este ranking son aquellos que producen películas y programas de televisión que tienen éxito en todo el mundo.---# Ranking de géneros por nota```{r}#Ranking/Valoración de los géneros en netflix-----#Seleccionamos los datos que vamos a utilizar y filtrarlos para quitarnos las notas sesgadas (pocos votos)df_generos_net <- df_netflix |>select(title, type, genres, score, votes) |>filter(votes>4000) |>select(-votes)#Vamos a desglosarlo, ya que una película puede tener varios génerosgeneros_net <- df_generos_net |>separate_rows(genres, sep =", ") |>filter(!is.na(genres)) generos_net$genres <-str_replace_all(generos_net$genres,"[\\[\\]']", "")#En un principio vamos a hacer el analisis sobre Moviesgeneros_net <- generos_net |>filter(type =="MOVIE") |>select(-type)#Eliminamos las categorías menos conocidasgeneros_net <- generos_net |>filter(!(genres %in%c("war", "sport", "european","family", "fantasy")))#Vamos a hacer un filtro seleccionando las 80 mejores peliculas de cada categoría y hacer la media#(Se va a crear un poco de sesgo pero al fin y al cabo es para que se vea mejor)generos_net_ordenado <- generos_net |>arrange(genres, desc(score))top_100_por_genero <- generos_net_ordenado |>group_by(genres) |>slice_head(n =80)nota_generos_net <- top_100_por_genero |>group_by(genres) |>summarise(nota_media =mean(score, na.rm =TRUE))nota_generos_net$nota_media <-round(nota_generos_net$nota_media, 2)nota_generos_net <- nota_generos_net |>mutate(genres =case_when( genres =="documentation"~"documental",TRUE~ genres ))nota_generos_net$genres <- tools::toTitleCase(nota_generos_net$genres)#GRAFICA ggplot(nota_generos_net) +geom_col(aes(x =reorder(str_wrap(genres, 5), nota_media),y = (nota_media -5) /5, # Escalar la altura de las barras al rango [0, 1]fill = nota_media ),position ="dodge2",show.legend =TRUE,alpha = .9 ) +coord_polar() +scale_y_continuous(limits =c(-0.7, 1), # Ajustar los límites a [0, 1]expand =c(0, -0.4) ) +scale_fill_gradientn("Nota media del género",colours =c("#252527","#6d625c","#410a14" ,"#ed0b0e") ) +guides(fill =guide_colorsteps(barwidth =15, barheight = .5, title.position ="top", title.hjust =0.5 )) +labs(title ="Valoración de las categorías en Netflix" )+theme(axis.title =element_blank(),axis.ticks =element_blank(),axis.text.y =element_blank(),panel.grid =element_blank(),plot.title =element_text(face ="bold", size =15, hjust =0.5),panel.background =element_rect(fill ="white", color ="white"),panel.grid.major.x =element_blank(),axis.text.x =element_text(color ="#252527", size =11, hjust =0.5),legend.position ="bottom",legend.title =element_text(color ="#252527") )```Esta gráfica muestra la valoración media de las categorías de contenido en Netflix, según las puntuaciones de los usuarios. Las categorías se ordenan de menor a mayor según el sentido de las agujas del reloj, yendo con un color más oscuro y negro, lás menos valoradas, a un rojo más vivo, siendo estas las mejor valoradas por la audiencia.En primer lugar, podemos observar como las categorías más mainstream son **más valoradas**, siendo estas **Drama** y **Comedia**, con una nota de *8.2* y *8* respectivamente. <br>A continuación tenemos un grupo de categorías, también muy bien valoradas con una nota muy similar, que oscilan entre *7.25* hasta *7.75*. Estas son Documental, Action, Thriller, Romance y Crime, de más valorado a menos.<br>Por último, se hallan las categorías **peor valoradas** de netflix, con una nota que va desde *6.4*, la menos valorada, hasta *6.8*. Entre estas podemos destacar a **Wester** y **Horrror** que son las peores.<br>En general, las categorías de contenido más valoradas en Netflix son aquellas que ofrecen historias complejas e interesantes, que pueden generar una mayor conexión con los espectadores y aceptadas por un público más amplio (son más para todos los públicos).En cambio, las categorías peor valoradas son aquellas que pueden ser polarizadoras o que pueden no ofrecer una experiencia tan gratificante para los espectadores.---# Series i películas más valoradas:::{.panel-tabset}## Top Series```{r}table_show_net <- df_netflix |>filter(type =="SHOW") |>filter(votes >70000) |>select(c(year, title, genres, production_countries, score)) |>arrange(desc(score)) |>slice_head(n=10)table_show_net <- table_show_net |> dplyr::rename( Año = year, Título = title, Géneros = genres, Producción = production_countries,Nota = score )table_show_net |>gt() |>tab_header(title =md("**Top 10** mejores **series** de Netflix"),subtitle =md("*Dentro de las más valoradas*")) |>tab_footnote(footnote =md("*Producción propia a partir de datos de `kaggle`*"))```Aquí podemos observar el top 10 de las mejores series de Netflix valoradas por el público, de forma descendiente.Práctiamente todas tienen una nota de excelente, pero hay varias cosas que se pueden observar. <br>En primer lugar, dentro del top, podemos ver como hay una clara predominación de series producidas en **Estados Undidos**, que puede deberse, o porque producen una mayor cantidad de series o que gracias a esto han aprendido y se han hecho **mejores cinematográficamente**. La más destacada "Breaking Bad"<br>En segundo lugar, podemos observar como **Japón**, con sus **animes** se apodera de prácticamente la otra mitad del podio, entre ellos "Death Note", "Attack on Titan" o "One Piece".## Top Películas```{r}table_movie_net <- df_netflix |>filter(type =="MOVIE") |>filter(votes >42000) |>select(c(year, title, genres, production_countries, score)) |>arrange(desc(score)) |>slice_head(n=10)table_movie_net <- table_movie_net |> dplyr::rename( Año = year, Título = title, Géneros = genres, Producción = production_countries,Nota = score)table_movie_net |>gt() |>tab_header(title =md("**Top 10** mejores **películas** de Netflix"),subtitle =md("*Dentro de las más valoradas*")) |>tab_footnote(footnote =md("*Producción propia a partir de datos de `kaggle`*"))```Aquí, podemos observar la misma tendencia, como Estados Unidos es la mayor productora de las mejores películas. <br>En cambio, podemos ver una curiosa casualidad y es que las 3 películas de El señor de los anillos estan dentro del podio, con notas que van del 9 al 8.8.## Buscador de contenido```{r}#Tabla para buscar informacióndf_buscar_net <- df_netflix_director |>select(-c(id, votes, popularity))datatable(df_buscar_net)```:::---# Directores con más películas```{r}#Gráfico de Nombres de TOP DIRECTORES en NETFLIX----df_netflix_dir <- df_netflix_director |>count(Director, name ="cantidad", sort =TRUE)df_netflix_dir <- df_netflix_dir |>filter(Director !="UNKNOWN") |>mutate(Director =as.factor(Director))wordcloud2(df_netflix_dir, size=0.6, color=rep_len( c("#B81D24","#564d4d"), nrow(df_netflix_dir)),backgroundColor ="#000000")```<br>Este gráfico representa a los directores con mas predominancia en los cines de Netflix de una forma más creativa, visual y bonita. Siempre respetando la paleta de colores de netflix. <br>Brevemente, se puede observar como el mayor tamaño de los nombres indica un mayor número de obras realizadas. En este caso, el mayor productor es Raúl Campos, seguido de Jan Suter y Ryan Polito.---# Información extraEn este trabajo me he inspirado en una web donde hay una galería de todos los posibles gráficos que pueden crearse con `ggplot2`, llamado `R-graph-gallery`, podéis acceder [aquí](https://r-graph-gallery.com/){target="_blank"}.<br>Por otro lado, este trabajo no hubiera podido ser posible si no fuese por `kaggle`, de donde he adquirido los dataframes y, además, me he inspirado de otros trabajos / gráficos. Podéis acceder [aquí](https://www.kaggle.com/){target="_blank"}.<br>Se ha intentado seguir una mejor coherencia durante todo el trabajo y se ha respetado a la perfección la paleta de colores que representa netflix.<br>Para finalizar, he de explicar que he modificado / alterado los dataframes a la hora de filtrarlos etc. Es decir, estan sesgados para que la representación sea más notoria y bonita. Por tanto, puede que en algún caso no coincida algún dato con análisis externos a este trabajo. <br> *Por ejemplo, el ranking de géneros por nota, si selecciono todas las categorías sin a penas filtración todos tienen la misma nota.*